Demo mode is up and running on twak.org. Originally designed for the vcg website, the leeds-wp-projects makes it easy for users to explore your content via the pages’ featured images in-line, or in a fullscreen demo mode (and the high-octane extreme demo).
Author: twak
videos of open-world games
Sometimes it nice to have videos showing people just how big open world games have gotten.
glitches in the matrix
The great thing about graphics research is that my bugs are prettier than your bugs…
thesis latex source
The source to the thesis is now available. This might be useful to people wanting to see what a thesis looks like from the inside (after being edited from multiple source and multiple authors). The .tex files aren’t a pretty sight, with more comments, deleted paragraphs and rubbish than I’d really like.
Build instructions:
- The thesis/mk.sh script will try to build dissertation.pdf
- Latexmk is used to find resources to rebuild
- Most of the images were created using inkscape, and would be best edited using the same.
- I used svg-latex for images. The setup will reprocess any svgs, using a command line call to inkscape. This means that latex has to be configured to run scripts (enable write18 is the magic google search).
- I’m sorry but I don’t have a record of all the latex packages required for the build. Those that aren’t in source are available in Ubuntu package manager.
There are some strange transparency rendering bugs in some images in the Chrome pdf viewer (below left). Adobe and Ubuntu Document Viewer (below right) handle them fine.
building better video
Strobee made me think quite hard about video, how we do it at the moment, and how would be done if we we started from a blank slate. What would video look like if it were invented for the first time today? What if there was only video?
Video has a lot of legacy components that need re-examining. Video used to be a hardware things, with tape and discs. Now it’s software; we all watch video on computers, but many of the old conventions are still with us. Even worse, the web was built for text (hTtp), and has bought it’s own conventions with it.
While trying to build a video platform, Strobee came up against many of these conventions, some of them helpful, others a hindrance. I’ve been collecting a list of them here:
- Why is every video the same every time, when our Facebook page is different every time we return to it? One of Strobee’s design challenges has been allowing this, as well as allowing visitors to revisit and link to videos they’ve seen before.
- Why do we always have to scroll down to see more video on Instagram or Vine? We are used to our web-browsers working as electronic-book-reading-machines. To accommodate this, the current web-video idiom is magical moving pictures on each page of the video book. Video is video, and should be fullscreen. The interface should be built around this ideal.
- Square videos are a fad, the world is starting to get over them. Our monitors, cinema, phones, and cameras seems to have settled on 16:9.
- Why does every video player need a play and pause button? They are legacy interfaces left over from hardware devices with actual buttons. There is no cost or side effect of not pausing a video. GIFs are a great example showing that we don’t need these controls any more.
- Long form video is a different media than social video. It has different conventions, constraints, and ways of viewing. My parents make appointments with TV – they’ve got to get home on time to watch 60 minutes of Inspector Morse at 9pm. To justify this kind of effort, video has to be 10s of minutes long, and once you’ve gone to all that effort, and watched something for 10 minutes, you’re trapped into to staying and watch the other 50 minutes.
- Strobee attempts to bridge the gap between long form and short form (micro-video) video – our video can be viewed in small sections, but also keeps playing endlessly, letting people who want to watch for 10s of minutes.
- Video navigation is a hard problem. It was very simple with cable TV: just pick a channel. Today we have many more variables possible (user, video clips, position in those clips, order of those clips, etc…). We experimented a bit, and just now Strobee has a fine-grain history (the clip gallery) along the bottom of the screen, and a course-grain explorer (the story navigator) up the right hand side of the screen.
- We should share video effortlessly and without thinking – in the same way we Instagram or tweet. We shouldn’t be worried that the video isn’t interesting to others or that the quality is lower than what we see on TV. We want to share our experiences using video with the click of a single button. Strobee is built to encourage this casual sharing. Clips are short, but what they lack in quality, they make up for that by both variety, and the interface’s ability to skip and explore.
- As with photos, some video clips are one-offs, but sometimes sequences of them tell a bigger story. Albums of photos can be more interesting than individual clips. When you look a photo album, you have to do the mental work to reconstruct the event – there’s no reason this shouldn’t work in video; there’s no reason, given the right format, why this shouldn’t be the case for video. Generating a perfect narrative (as we see in cinema), requires exact planning to capture every event – a totally different philosophy to the photo album.
- Unwatched video is a massive opportunity! Today, some of us have lots of video, in the future all of us will have lots of video. People with action-cameras (GoPros), are notorious for recording footage they never watch or share. They return from holiday with full memory cards, few have the patience to watch it all, fewer share any, and fewer still take the time to create a video that others would actually want to watch. It should be easy to share bulk footage like this, Strobee makes it a little easier, but there’s a long way to go…
I don’t think Strobee addresses half the issues that it could, and I expect to see many more imaginative video sharing platforms in the next few years. Weaning people off their old platforms and conventions will be tough, but progress is being made everyday. Strobee has a long way to find the best way to explore video, and we’re totally stoked to be at the forefront of these challenges!
Solve all Java errors
frankenGAN pretties
Here’s some of the renders from the FrankenGAN project’s presentation last week at Siggraph Asia. Blender animations. Full slide deck.
And another high-res teaser-style image:

scary monsters and nice robots
the bits that didn’t make the FrankenGAN paper: using GANs in practice (now we’re conditionally accepted to siga this year):
Conditional GANs learn to convert one image to another (for example a blank facade to a facade with window-labels). To do this they must be trained on a large set of examples. We used a bunch of these GANs to convert simple building shells…



…into detailed geometry and textures:
Every facade, roof and window has a unique texture (rgb, normal and specular maps) and layout. You can control the style generated by giving the system style-examples for each building part (roofs, facades…)
FrankenGAN uses a bunch GANs to greeble buildings. One GAN goes from blank facade to window locations, another from window locations to facade textures, another from facade textures to detailed facade labels (window sills, doors…), another from window-shapes to window labels etc…
A cynic might suggest was that all we did was solve every problem we encountered with another conditional GAN. An optimist might say that it shows how we might build a CityEngine that is entirely data-driven.
Let’s continue to look at some of the caveats to training so many GANs in the real world…
robots! Our training was plagued by “localised mode collapse” (aka Robots). In the following we see that the network hallucinates the same detail block again and again, often in the same location.

In many of our full-facade tests these appeared as red-dots at street-level (look closely in the following images) – we had many problems with red “eyes” appearing in the shop windows. We named these guys robots because of we came to dread viewing our network outputs after a night of training, only to find these red eyes looking out of the shadows of our buildings.


There was no cure-all solution to this problem. Two things that we found helped:
- Selecting the final training epoch. It seemed that it was never possible to completely get rid of robots, but it is possible to select which ones you get. By carefully selecting the training epoch to you, we found those with acceptable mode collapse. There were always some collapses.
- Dropping entries from the datasets. Our red-eyed robot seemed to be caused by red tail lights on cars at street level. Because we had relatively small datasets, it was possible to manually remove the worse offenders. Removing 1-5 entries seemed to make a difference sometimes.
the art of the dataset… There is an argument that FrankenGAN-like pipelines take the artistry out of creating textures. And certainly, you should get “optimal” results by an unbiased sampling of a large number of textures in your target area. However, because of cost and the quantity of data required, we are usually forced to choose our datasets carefully to contain the features we wish to generate. As an example, let’s stitch a new (body) part onto our FrankenGAN: doors. To get going I gathered a bunch of door images from around the internet and fired up our modified BicycleGAN.
Network input was just a single rectangular label giving the shape of the door:

and output are our door pictures. So our training data was ~2000 pairs of red rectangles, and corresponding door textures.
Gathering this data is the major artistic process here. Imagine teaching child to draw a door – which examples would you show them? You want them to learn what a door is, but also want to understand the variety that you might see collection of doors. GANs tend to lock onto the major modes, and ignore the more eccentric examples. So if you want to see these there had better be a bunch of examples illustranting them. The bulk of the door dataset I put together is regular doors, with a few extra clusters around modern and highly ornate doors to keep thing interesting.
After 400 epochs training (200 + 200 at a decreasing learning rate, 10 hours of training) the results here. We had some nice examples:


But we ended up with issues around arched doors, and the interface between the walls and doors was poor. I also made a content decision: there were too many wooden doors. These were art-chain related decisions: our geometry engine always gives square doors, and expects a door texture to mostly fill this rectangle.



So the solution was to edit the dataset…to remove some wooden doors, and examples with arches and too much wall. In this case we’d shown our child too many strange examples, and they kept drawing them for us. Even though the dataset fell from 2000 examples to 1300 examples the results were generally better, for being more focused. Every second it’s possible to manually view and possibly delete multiple images, so this can be done in less thank an hour (although you get strange looks in the office, sitting in front of a monitor strobing door images, furiously hammering the delete key). Results here. Each training run was an overnight job, taking around 9 hours on my 1070.




These are looking good, given that we don’t have labels (like the FrankenGAN windows and facades). But there were still some problems.
At 200 epochs the learning rate starts decreasing, however at this point the results weren’t good. So we’ll also bump the training to 300 epochs at constant learning rate, before decreasing for a further 300.



I also felt like the results were too soft, so I decreased the L1 weight (–lambda_L1 parameter in BicycleGAN) from 10 to 5, to give the adversarial loss (generally encourages sharper images, at the risk of having too much local detail) higher priority. Aaand we leave the computer training overnight again to get the next set of results.




Being a GAN there are still some bad samples in there, but generally we have pushed the results in the direction that we need them to move.
As we see creating the dataset and training parameters is an involved iterative process that takes knowledge, artistic license, and technical ability to solve. I don’t pretend to have any of these things, but I can’t wait to see what real texture artists do with the technology.
So there are a many of artistic decisions to made when training GANs, but in a very different way to current texturing pipelines. Game artists are particularly well positioned to make use of GANs and deep-texturing approaches because they already have the big expensive GPUs that are used to train our networks. I typically use mine to develop code in the day, and to train at night.
Maybe future textures artists might be armed with hiking boots, light probes, and cameras rather than Wacoms and Substance; at least they will have something to do while their nets train.
regularization (this did end up in the final paper thanks to the reviewers). Because we applied GANs to known domains (facades, windows, roofs…) we had a good idea of what should be created, and where. This allows us to tidy up (regularize) the outputs using domain priors (we know windows should be rectangular, so we force them to be rectangular). So we can alternate GANs which create structure (labels) and style (textures), which allows basic regularization to happen in between. Because the regulators are out-of-network, they don’t have to be differentiable…and could even be a human-in-the-loop. This gives a very reliable way to mold the chaotic nature of a GAN to our domain.
For example, our window results are much stronger than the above door results because we had window labels (which Piensa created for us). We were able to regularize the windows to make sure they were always rectangular. Here’s some windows to compare.
Top row: left: one GAN creates “blobby” window locations. middle: we fit rectangles (using openCV’s dilate/erode functions for a bit of robustness). right: a dirty mean-shift implementation moves the rectangles to more window-like positions. Bottom row: Similarly for facade decorations – we note that regularization can make even bad network outputs acceptable.

In addition, because the domain of the GANs used is tightly controlled (we do the facade, then the roofs, then the windows), it acts a inter-GAN form of regularisation. We only get facades on the front of buildings etc… Obvious, but very powerful when we have good models for your domain.
super super networks. Our super-resolution network was a little bit last minute and hacked together. It took the low resolution GAN outputs (256×256 pixels) and ran a super-resolution GAN to create an output of around 80 pixels per (real-world) meter. Unlike most existing super-resolution networks, we wanted the results to be inventive and to include a stylistic element (so some blurry low res orange walls become brick while on another building it could become stucco). The architecture had the advantage that it used a very similar pipeline to the other networks in the paper, but we had earlier plans to do something different.
Here is an early mock-up of a low-resolution facade texture with a high resolution texture overlay. Here I used a blender shader to mix in a high frequency “brick” texture to the facade.

In this scheme we would learn to generate this high-resolution tiled texture from an image of the facade. The goal would be that red coloured facade would have a red-brick tiled high detail texture, while a grey coloured facade would have a concrete high detail texture. This could be achieved with a dataset of whole facade to detailed texture, and a similar GAN setup.

Having a GAN generate tiling textures would be a bit of a research project, but I’d hoped that having the adversary see the “tile seams” should give reasonable results. Collecting the dataset proved the downfall here – we would have needed many pairs of high-resolution facade, and clean texture images. We didn’t have the time, so this idea was never implemented. (Get in touch if you want to help implement it!).While we’re talking about super-resolution, here’s the results from a network that didn’t quite work…but produced some unique art. It always reminded me of the beautiful art in the video game Dishonoured somehow.



The super-resolution style results presented in FrankenGAN were never very strong. The underlying colour tended to overwhelm the style vector to determine the results. This was a common theme when training the networks – the facade texture network had a tendency to select colour based on window distribution. For example missing windows in a column were frequent in NY (they were occluded by fire escapes), so the texture network loved to paint these buildings brick-red.
However, we generally overcame this problem with BicycleGAN to make the nets do something useful; we can clearly see some different styles given the same low-resolution inputs:


When combined with the window and roof networks, this gave nice results (but the style variation was rushed and sub-par).

We also cheated a little by drawing some high-frequency rectangles into to low-resolution map. These emphasised / helped to position window-sills and roof flashing (magenta), and hid errors such as as “bleeding” around the edges of the textures. Below left: roof-edges passed into the low-resolution network; middle magenta: those edges in 3D; right: the super-resolution with the these edges painted in as roof-flashing.


We see that variety in the types of network and domain (windows, facades, roofs) come together to create a very strong effect. This “variety synergy” seems to be enough to stop people looking too closely at any one texture result. We were somewhat surprised to get results looking this good just a week before the deadline (and then had to write a paper very quickly about them…).
A nice side-result was using super-resolution to clean up images. Here we see an early super-resolution result (fake_B) removing the horizontal seams from Google Streetview images (real_B) by processing a heavily blurred image (real_A):

building skirts. A fun early result was generating the area around buildings (aka skirts). Here the labels (top left) were transformed into the other textures:
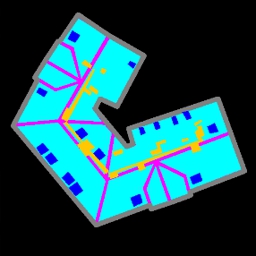



What is nice here is the variety in the landscape, and how it adapts to the lighting. For example, on an overcast day the surrounding area (bottom left) looks much less green than a similar texture in the “day”. More results. The final roof results in FrankenGAN lost all this “skirt” texture because of some of the network conditioning we applied.
tbh they don’t look great in 3D, they have no idea how to synchronise with the building geometry, so there are problems such as the footpaths not leading to doors.

patch based realism. One of many failed attempts to improve the GAN pipeline was to patch-based realism. The concept was that the GANs adversary would only see many small patches of results + labels. In this way we hoped to reduce the influence of the input label maps on the output style. We can create a patch tensor from data (below; top 2 rows) and during training (bottom 2 rows):

We can then train a patch-style discriminator. It is trained on different photographs of real facades; and tries to guess if the patches are from the style (or just the same source image). We can then use the network to evaluate the style of a network output.
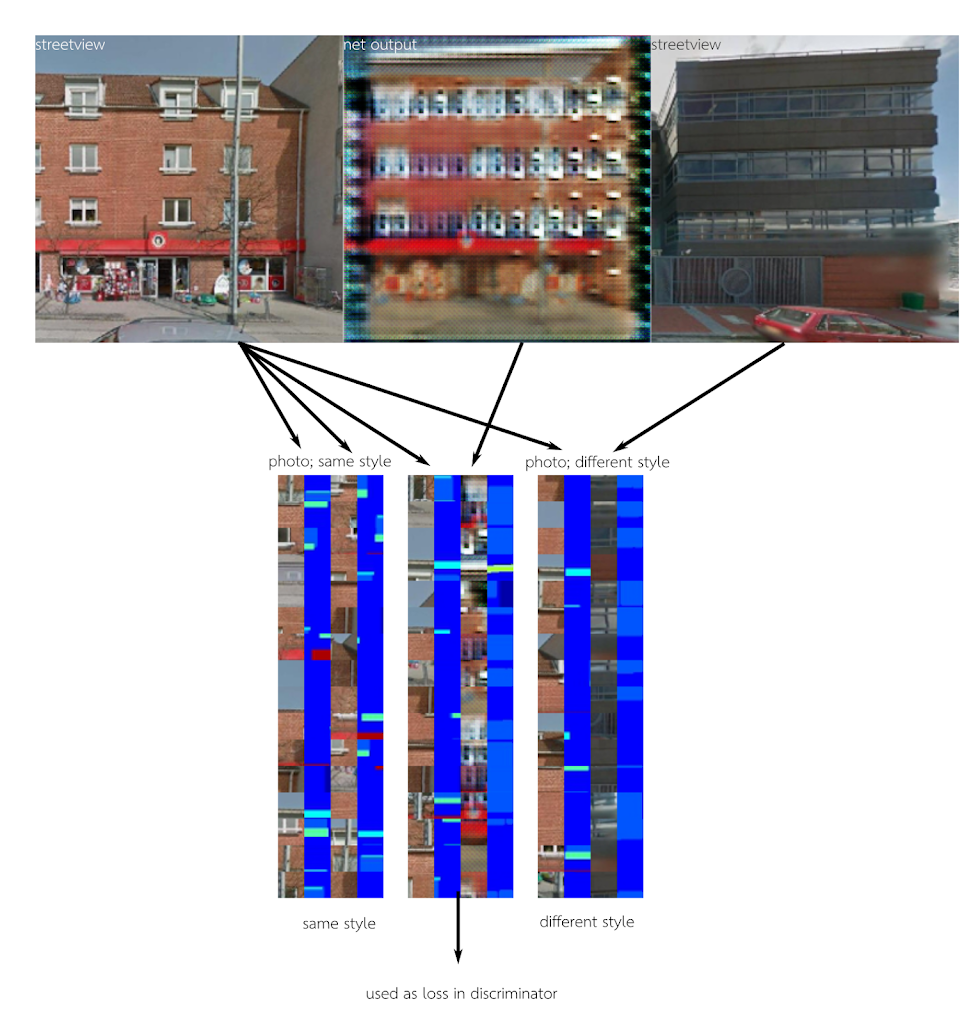
Even though the patches were randomly located, the results ended up with many repeating textures at the frequency of our patches.





While these results have “artistic” merit, there weren’t really what we were looking for. However, we note that that the window reconstruction, and repeating pattern (when close to our patch size) was very strong. Perhaps multi-scale patches might help in a future project [edit: CUT did something similar to this is 2020]…
relationships
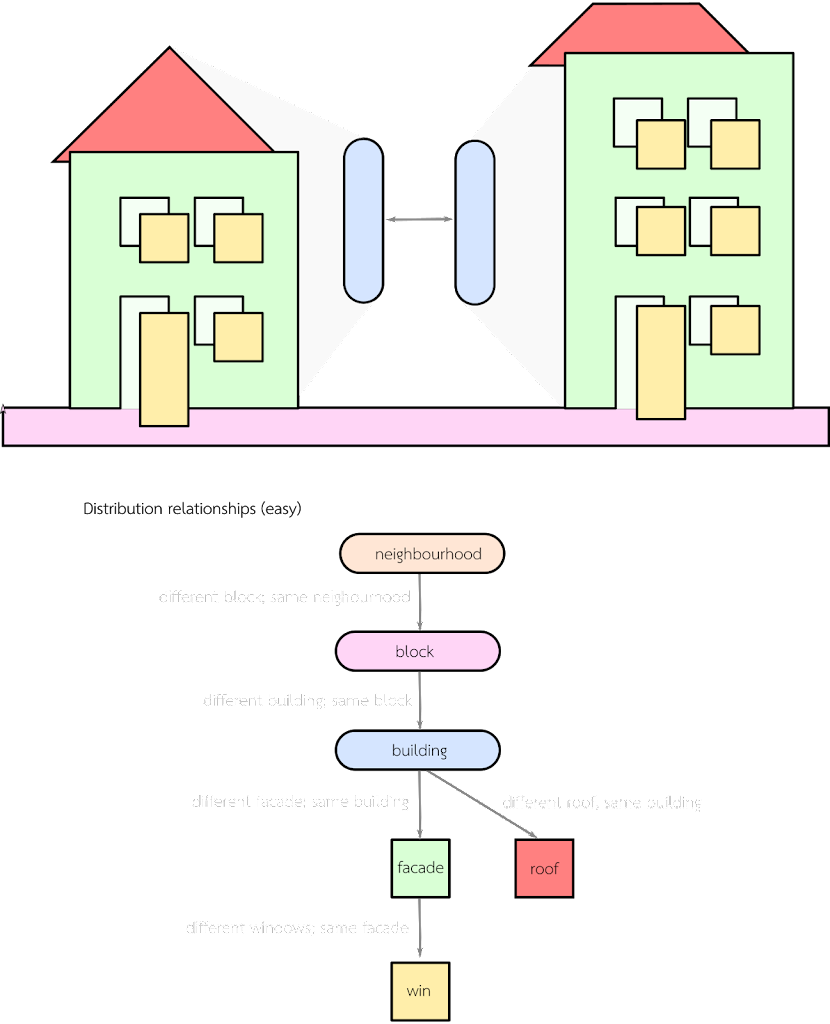
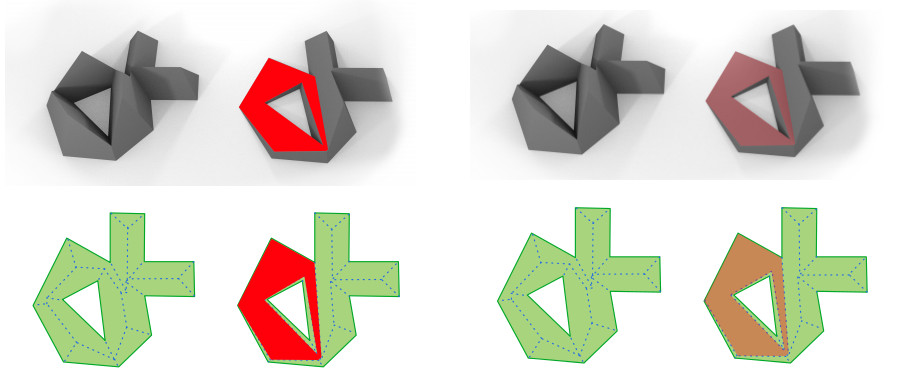
Something that was never investigated further was the design-space around how style distributions interact. The paper presents a simple scheme, in which each building selects style vectors for all its children (facades, windows, roofs…). These style vectors determine the style of each child – things like window spacing or facade colour. For example, they determine which style of door is created from the red input rectangles above.But, for example, we may occasionally want one wall of a building to be a different colour than the others, or perhaps the windows distribution on different sides of a building changes. Or even every window to be different to its neighbours (if you look closely you’ll see that a bug in the causes this to happen in Figure 6 in the paper).
To support these kinds of operations, the software support a bake-with descriptor for the distributions. This determines which of the parents a child’s style vector is re-drawn with. So, for example the window style could be determined at the block, building, or facade levels…or be re-sampled for every window (if bake-with is ). This functionality is controlled with this combo-box in chordatlas:
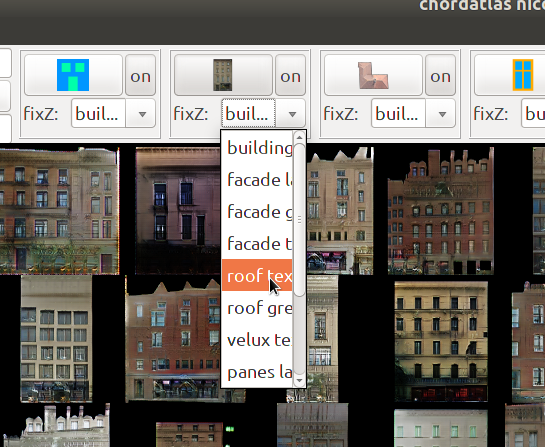
The next steps in this direction might be
- a probabilistic bake-with: so that there’s a 10% the window style is baked at the block level, 30% chance at the building, and 30% at the facade level.
- geometrically driven bake-with: so facades which face the street might have a different style than those who face their neighbours.
frankenGAN? The title was never explained in the paper. I made the name up as a joke about our ad-hoc datasets…and it kind of stuck. Collecting the data for a project like this was a challenge. Each GAN needed 500-3000 example image pairs to train. We paid for the facades, roofs and the windows to be manually labelled, but we could not find source photographs from a consistent area. So we ended stitching together datasets from different locations – leading to Franken(stein) GAN: The windows of Regent Street, with the roofs of Milton Keynes, and Germanic facade layouts. These parts were stitched together into the unholy abomination we loosed upon Siggraph.
The name turned out to be particularly apt because our final networks were very keen to paint green “slime” over our walls (although I’m reliably informed that the original Frankenstein’s monster was grey…).
I have no doubt that “real” geospatial scientists will, one day, provide us with coherent datasets, hopefully this paper gives them the excuse they need to get the funding to do it for us lazy graphics people.
where next? I had wanted to use GANs to create “stylistic” specular and normal maps, but never got around to it. In the end I hacked together something very quickly. This took the RGB textures, assumed depth-from-greyscale value, and computed the normal and specular maps from these. Use the layers menu in sketchfab to explore the different maps (yes yes, I know the roof is too shiny):
Assassin’s Creed Syndicate was released back in 2015, and makes our results look small-scale and poorly textured. Of course, our results took me “only” 1-4 hours to create while Creed games might have a budget of ~$1e7. The obvious next step is to scale up the area reconstructed, the resolution of the networks, number of training examples, and depth of the frankenGAN. I always wanted to see if we could create a network to add drainpipes to facades, individual bricks to walls, and street furniture to streets. video:
Finally, the folks over at /r/proceduralgeneration liked our results (and /r/MachineLearning) but wanted interactive generating speeds. When being used the implementation only uses about 10% of the GPU’s capacity, so there are some big gains to be made there. Further, offloading the GPU stuff onto several cloud machines could give a big speedup. But I think what would be really nice is simpler / faster CGANs that can give us similar results.
openGL pipeline
loading the street view trike
Trawling streetview images you often see some strange things. Here’s some panoramas from unloading the streetview trike. Back in 2012 google’s quality control wasn’t was it is now…





Around the corner we can see reflections of the same bespectacled guy riding the trike around Soho…


{kind=link}